Hello, ZK-Wordle!
In this article, let’s take a closer look at the implementation details of our ZK-Wordle app. You can find the complete app code here and try out the production deployment here. The previous article covered the app architecture. So, let’s once again take a look at the sequence diagram that we initially presented there.
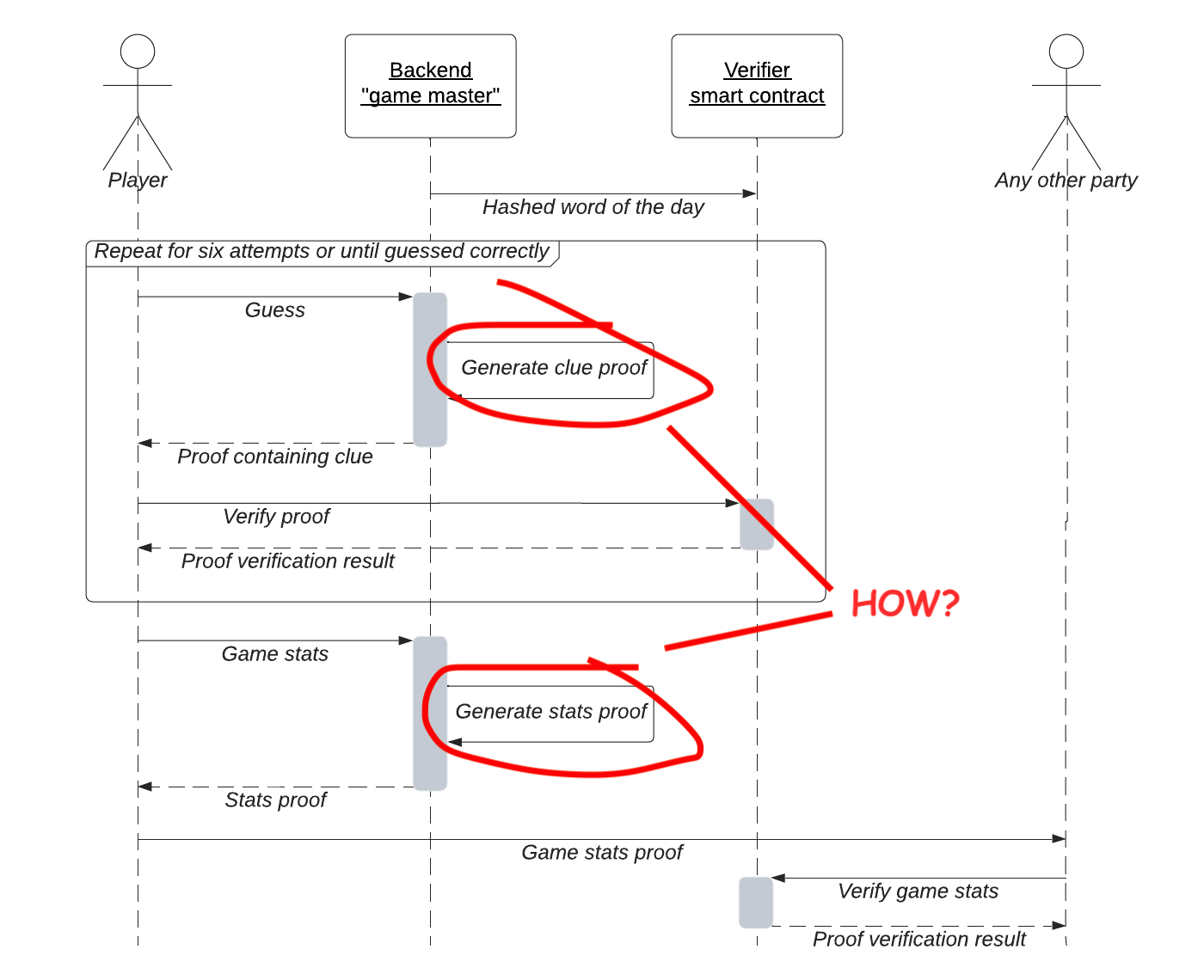
f, and now it’s time to peek inside them. One of the recently most popular ZK-proof constructions is zkSNARK. This beast is no friend to a fellow software engineer because it is neither a framework nor a language or utility. It’s a cryptographer’s creation that, in its original form, lives on the pages of academic papers. Fortunately, there is a more usable representation in the form of a set of software tools developed well enough to make the full-stack ZKP applications possible. Buckle up because things are getting a little complicated here. Currently, no single utility allows you to describe, generate and verify the proofs in one go. The following diagram can help to explain why it’s the case.
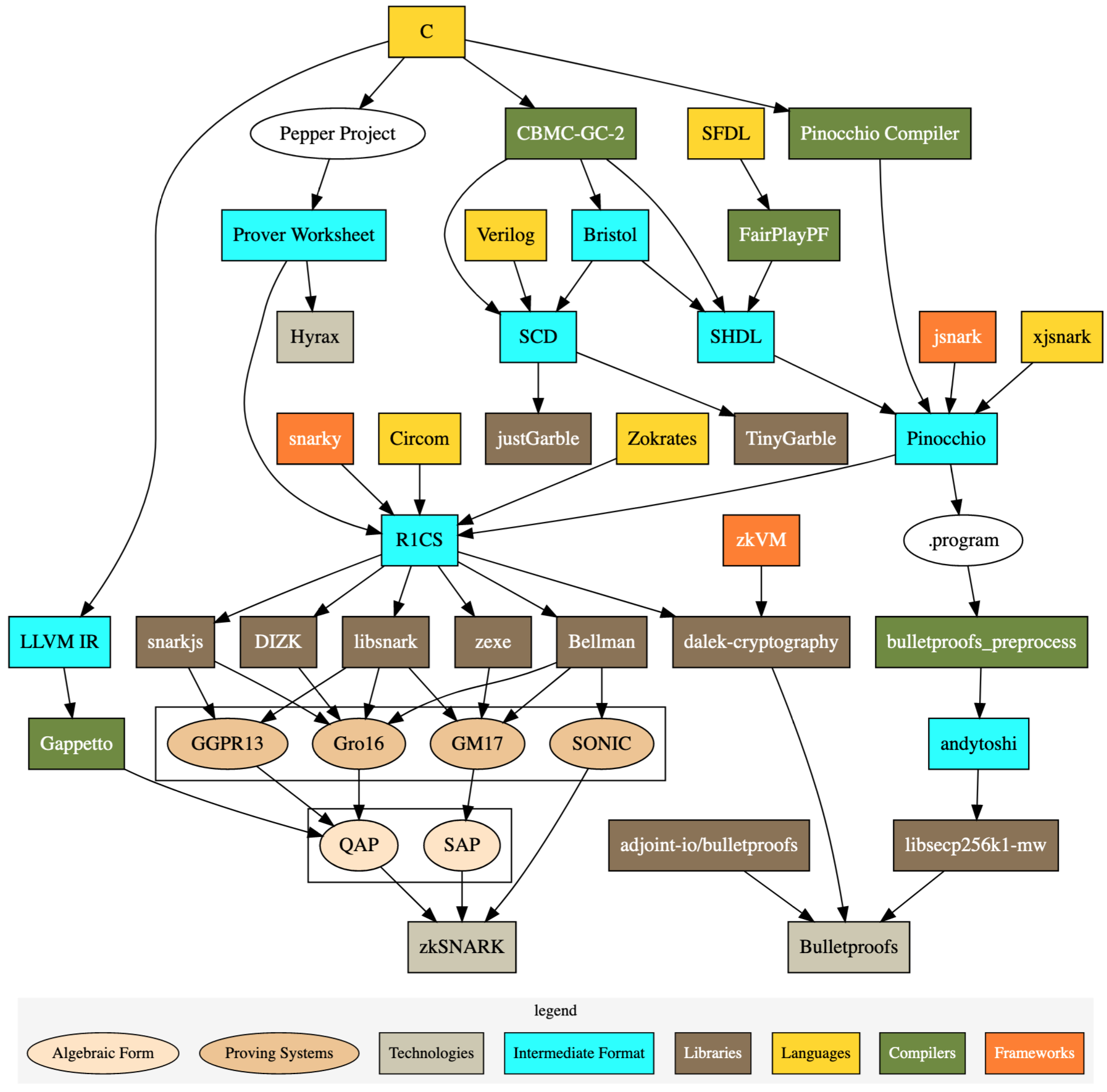
Describing Circuits With Circom
Circom allows us to describe statements we’re proving in the form of circuits. Circuits are similar to computer programs, but some significant differences need our attention. So, let’s look at the circuit that proves the clue’s correctness.
Don’t be surprised if the circuit code looks clumsy to you. You might wonder why there are no convenience methods in Circom that allow you to do things like array.contains(), why you should check the equality using a special IsEqual() object (by instantiating a so-called template) instead of simple ==, and possibly for other reasons.
The reason is that Circom has to transform our circuit into a polynomial for further SNARK construction. Polynomials possess properties that are highly beneficial for proving statements. The idea of representing a computation as a polynomial might seem bizarre, but some brilliant maths makes it possible. The exact reasons why SNARKs require polynomials are out of the scope of this article, but if you’re curious about the inner workings of SNARKs, I suggest you study the maths behind them. For now, let’s try to use a couple of toy examples to demonstrate the properties of polynomials that are intuitively helpful in constructing the proof. First, a polynomial contains an unbounded amount of information. It allows us to put the “useful” information in it and, at the same time, hide it among the much more substantial amount of “dummy” information (recall that any polynomial is passing through an infinite number of points). Second, a polynomial is very easy to evaluate computationally - it requires only simple arithmetic operations that don’t demand significant computational power, allowing for fast proof verification. For example, imagine the difference between the computing power needed to hash a sum of n numbers and to evaluate a polynomial of the degree n at some point. With all that said, a check written as x == y doesn’t very much look like a polynomial, so we’d better write it as x - y == 0. That is why Circom requires specific components for some actions as trivial as an equality check.
Another surprising use of polynomials in SNARKs is that they allow the prover to convince the verifier that the proof was obtained by performing the actual computations in the necessary order and not by coming up with the result in some other way. Polynomials do that by encoding a trace of calculations. It leads to the absence of some dynamic constructions in Circom. For example, we cannot use the input signals in conditions or dynamically break the loops. Such actions would make the computation sequence dynamic and not fixed, making it impossible to describe it using a single trace. You can think of it as an electric circuit. Once the circuit components are soldered onto the board, they don’t change. The entire signal flow is already defined. Circuit components can process signals in complex ways, but the signals should always flow through them.
Wordle Circuit In More Detail
Our primary circuit generates the clue based on the player’s guess and the solution known to the backend. Lines 19 to 104 perform various comparisons between the guess' letters and the solution letters and encode the clue according to the following convention: 1 represents an exact match (displayed as 🟩 on the frontend), 2 represents a letter that is present elsewhere in the solution (🟨), and 0 designates a letter that is not present in the solution (⬜). Circom signals can only be numbers, so we supply all the letters as their corresponding ASCII codes.
Lines 113 to 123 ensure that the solution used to obtain the clue is precisely the one generated at the beginning of a game round. They check that the solution commitment matches a hash of a solution and a random salt. This constraint allows players to trust the backend not to swap the solution for something else while generating clues. Since players can be sure that the backend used the correct solution, they can also trust the resulting clue. Salting the hash is an excellent addition to the recipe (pun intended) to make it resistant to a rainbow attack. In our case, a rainbow attack is possible because all possible solutions are publicly known. Therefore, the backend generates a new random salt for every game round.
One minor but significant difference between the circuit that proves the individual clues and the circuit that proves the validity of the game stats is that for game stats, we should keep the guesses unknown to verifiers. Therefore, we do not declare them as a public input of the circuit, leaving only the solution commitment. The beauty of zero-knowledge proofs is that they don’t necessarily need public inputs; ultimately, you can create circuits with only private inputs and still generate proofs that anyone can verify.
Compiling Circuits
Once we have described the circuit, we can compile it into formats appropriate for our backend and client applications. You can find the script that takes care of the compilation here. First, Circom does the polynomial transformation magic mentioned above by converting the circuit into an R1CS representation. It is stored in a WebAssembly module that is convenient to run inside our JS backend. Then, snarkjs finishes it off by generating some prover parameters and a verifier. The verifier is a smart contract we deploy on blockchain to be easily accessible by any player’s frontend. Snarkjs offers two proving schemes - Groth16 and PLONK, that employ different compilation procedures and produce significantly different results. PLONK seems to be a convenient solution because it does not require a so-called trusted setup (mentioned in the previous article), and it’s enough to use the pre-generated powers of Tau files. Compiling with Groth16, on the other hand, requires the circuit-specific phase of a trusted setup that ideally involves multiple interested parties who make secret random entropy contributions. Sounds complicated, I know. That’s why I initially chose PLONK and had to regret it later! Let me tell you why. Everything went smooth until I had to deploy the backend. I set up the automated Heroku build and prepared to push the compiled circuit for the first time. The push refused to go through, and I went to investigate only to discover the game stats circuit zKey file of several hundred MB in size! That looked very wrong for a seemingly unsophisticated application like this. However, when I looked closely at the compiled circuit parameters, I realized that the difference in how Groth16 and PLONK describe arithmetic circuits drastically affects the compiled circuit size. Here’s the table for comparison; notice the constraint number:
| Proving Scheme | # of Constraints | zKey Size | Prover Time1 | Verifier Time2 |
|---|---|---|---|---|
| PLONK | 17251 | 207.8 MB | 24998 ms | 46 ms |
| Groth16 | 2610 | 1.5 MB | 735 ms | 56 ms |
As you can see, the zKey file size reduction under Groth16 is worth the security tradeoff of having a trusted setup for this particular application. A trusted setup conducted by a single party (me in this case) allows this party to create false proofs. So, in the worst case, you can see me sharing false ZK-Wordle proofs on my socials! For a more serious use case involving user funds or sensitive data, it is necessary to conduct an actual multi-party trusted setup. Feel free to send me a message if you’re willing to contribute to the trusted setup for this app! Another benefit of Groth16 that we can see here is an almost instant proof generation (even less for individual clues, not specified in the table). It provides a smooth user experience similar to the original game.
Putting It All Together
Let’s now follow the app sequence diagram along with the code. First, we must commit to the word of the day solution. We expect the backend to create the commitment because only the backend knows the solution at the beginning of the game round. However, putting the commitment on-chain requires paying the transaction fee, and we don’t want to bother maintaining a positive balance of the backend account. So instead, the backend delegates the blockchain transaction to the first player of a round. Next, the player can start playing the game as usual. The frontend is using a modified Wordle clone made with React. To be able to query the smart contract for proof verification, the player needs to connect their wallet. When a player submits a guess, it goes to the backend, which generates the proof in return. The frontend immediately verifies the proof by calling the corresponding smart contract method. The apparent visual difference with the original Wordle is that our ZK version indicates the correctly verified clues. When the game round is over, the player can generate the entire game stats proof to share on social networks. Additionally, we let the players verify others' stats by pasting them into the input field below the game grid. Under the hood, the frontend performs a smart contract call similar to the clue verification and displays the result.
Conclusion
What if I told you that our ZK-Wordle is not entirely zero-knowledge? It turns out that the colored clues shared on social media contain enough information to analyze them en masse and figure out the solution on the first guess, as proven by some data science folks here! In our case, we could easily make the game a “true” zero-knowledge by removing the clues from the shared message. In such a “hardcore” mode, players would still be able to prove that they beat (or lost) the game in a certain number of steps, but it would arguably kill the game’s social aspect. Games should be fun and exciting, as well as the process of learning contemporary cryptographic technologies 😉
I want to give special thanks to Chih Cheng Liang for his valuable feedback.